通話を AI エージェントに転送する
早期アクセス
AI エージェントへの通話転送 エレメントを使用して、IVR (自動音声応答) フローからリアルタイムの Voice AI エージェント にアクティブな通話を引き継ぎます。これにより、音声認識、意図検出、生成 AI を使用して、通話を自然に会話で処理できるようになります。
コールがフローのこのエレメントに到達すると、IVR (自動音声応答)は、選択した AI エージェントに制御を転送します。エージェントがタスクを完了すると、コールは常に IVR (自動音声応答)に戻り、コールが返された理由に関する情報が表示されます。
AIエージェントの詳細については、AIエージェントのドキュメントを参照してください。Voice AIエージェントの概要は、「Voice AIエージェント」を参照してください。
エレメントのサイドパネルで、次のフィールドを設定します。
AI エージェントの選択
これは必須フィールドです。 メニューから、マイエージェントページで作成したAIエージェントを選択します。
エージェントのバージョンを選択
エージェントのバージョンを選択します。既定の設定は 常にアクティブなバージョンを使用する です。
Voice処理
AI エージェントの処理タイプを選択します。
-
音声読み上げ: 単一の AI モデルが、テキストに変換することなく、音声で直接聞いて応答します。これにより、より高速な応答とより自然なトーンが可能になりますが、1分あたりのコストが高くなる可能性があります。
-
音声からテキストから音声へ: Voice は最初にテキストに書き起こされ、言語モデルによって処理されてから、音声に変換されます。このアプローチはコスト効率が高く、より優れた制御と簡単なデバッグを提供しますが、追加の処理手順により追加の遅延が発生します。
音声読み上げと音声テキスト読み上げ処理のどちらを選択するか
| 検討 | スピーチ・トゥ・スピーチ | 音声テキスト読み上げ |
|---|---|---|
| 対応言語 | 日本語 | 広い範囲。Web インターフェイスで言語構成を確認します。 |
| エンドツーエンドのレイテンシー | 最低 (約 250 から 500 ミリ秒) | 良好 (約 500 から 1500 ミリ秒) |
| 成績証明書の可用性 | 利用可能。品質レビューに役立ちます。 | 利用可能。品質レビューに役立ちます。 |
| Voiceの自然さ | 非常に高い。ネイティブオーディオモデル。 | 高い。音声の選択によって異なります。 |
| 最適な用途 | 英語のみでレイテンシーが重要なユースケース | 多言語、コスト重視、またはコンプライアンス重視の導入 |
スピーチ・トゥ・スピーチ [#speech-to-speech-agent-type]
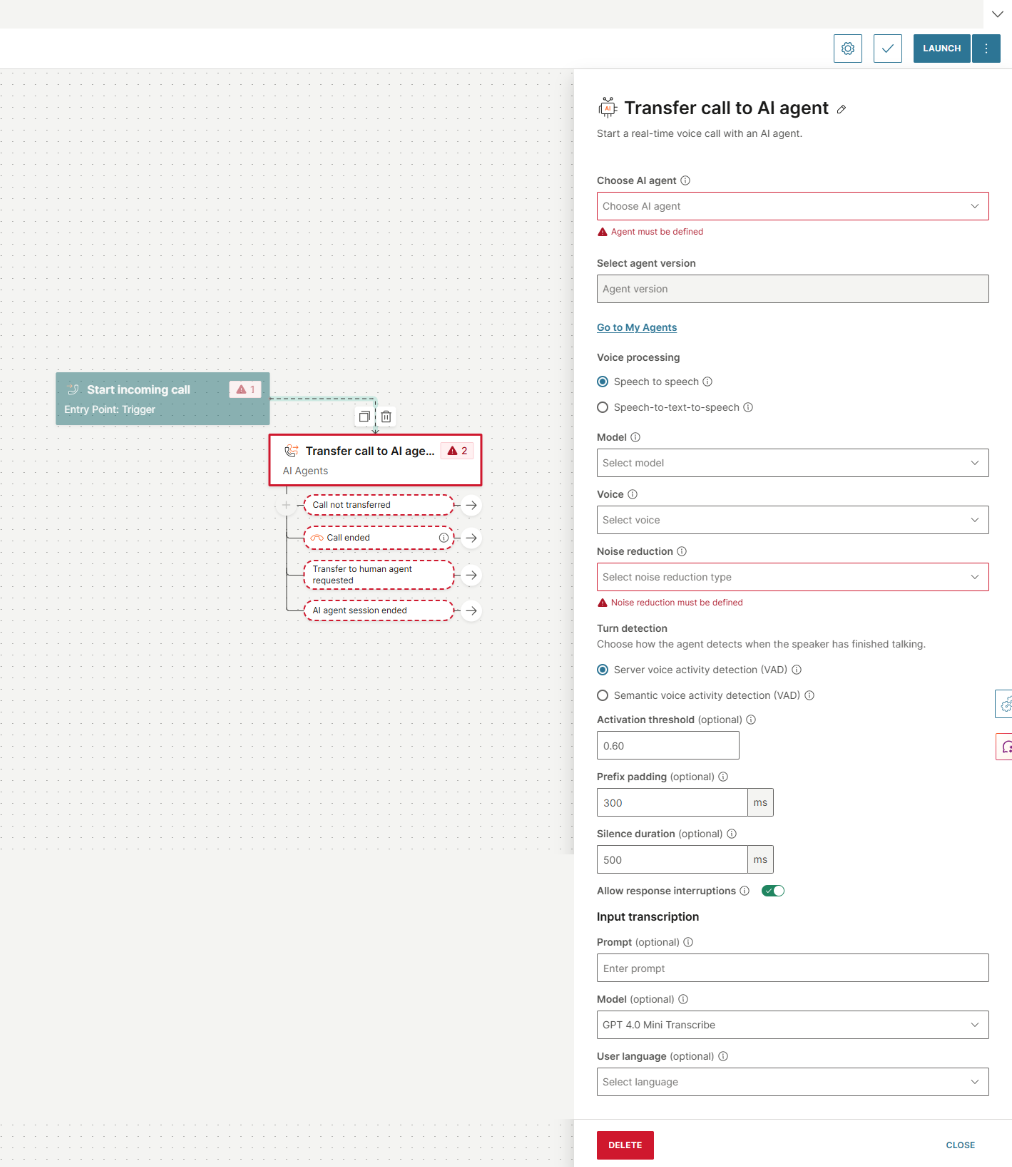
音声読み上げ を選択した場合は、次のフィールドを構成します。
- モデル: 応答のモデルを選択します。フルバージョンとミニバージョンの両方のリアルタイムモデルから選択できます。
- Voice: これは必須フィールドです。モデルが応答に使用する音声を選択します。
- ノイズリダクション:これは必須フィールドです。ノイズリダクションのタイプを選択します。近距離のマイク(電話やヘッドフォンなど)には近距離フィールドを使用し、遠距離で使用されるマイク(モバイルスピーカーフォンや会議室のセットアップなど)には遠距離フィールドを使用します。
ターン検出
スピーカーが話し終えたことをエージェントが検出する方法を選択します。
-
サーバー音声アクティビティ検出: サーバー側の音声アクティビティ検出を使用して、ユーザーが話し終えたタイミングを検出します。このモデルは、音声レベルを監視し、無音時間を測定し、ユーザーが話し終えた確率に基づいて応答タイムアウトを調整します。これは、無音の解釈方法を予測可能で構成可能な制御が必要な場合に使用します。
-
セマンティック音声アクティビティ検出: セマンティック分析を使用して、ユーザーがいつ話し終えたかを検出します。このモデルは、ユーザーの言葉が完全な思考を形成しているかどうかを評価し、その確率に基づいて応答タイムアウトを調整します。このアプローチは、バックグラウンドノイズに対してより耐性があり、文の途中で自然な一時停止中にユーザーを遮断する可能性が低くなります。
-
アクティブ化しきい値 (省略可能): 音声アクティビティ検出の感度を 0.0 から 1.0 のスケールで設定します。値を大きくすると、音声として登録するためにより大きな音声が必要になるため、ノイズの多い環境での誤ったトリガーが減少します。値を小さくすると感度が上がり、静かな設定や物腰の柔らかいユーザーに適しています。
-
プレフィックス パディング (ミリ秒) (オプション): プレフィックス パディングは音声クリッピングを解決します。VAD は音声が開始されたことを検出するのに時間がかかるため、検出がトリガーされる前に最初のミリ秒の音声が失われます。プレフィックス パディングは、オーディオ バッファーをわずかに巻き戻して、その事前検出オーディオを再キャプチャするため、モデルは実際の開始から完全な発話を受け取ります。
-
無音時間 (ミリ秒) (省略可能): 音声が終了したと見なされるまでに、何ミリ秒の連続無音が発生する必要があるかを設定します。値を小さくすると、エージェントの応答は速くなりますが、文の途中での自然な一時停止が中断されるリスクが高くなります。ノイズの多い環境や、ユーザーが思考を完了するのにさらに時間が必要な場合は、700 から 1000 ミリ秒を使用します。より高速で応答性の高いエクスペリエンスを実現するには、200 から 400 ミリ秒を使用します。
-
応答の中断を許可: 有効にすると、ユーザーが再び話し始めると、AI は現在の応答を停止します。
セマンティック VAD 構成
-
熱意: ユーザーが話し終えた後のエージェントの応答速度を制御します。高 は、スピーチの終わりが発生したとすぐに応答します。低 は、ユーザーが終了したことを確認するまでより長く待つため、エージェントが思考の途中で中断する可能性が低くなります。中がデフォルトです。
-
応答の中断を許可: 有効にすると、ユーザーが再び話し始めると、AI は現在の応答を停止します。
両方の VAD タイプに対して次のフィールドを設定します。
入力文字起こし
-
プロンプト (省略可能): テキスト文字列を入力して、文字起こしモデルを会話で予想される語彙、スペル、言い回しに偏らせます。このフィールドは、認識エンジンへのヒントとしてのみ機能します。これは、オーディオがテキストにデコードされる方法には影響しますが、モデルの会話動作は変更されません。固有名詞、頭字語、ドメイン固有の言語など、モデルが聞き間違えたり、一貫性のない文字起こしをしたりする可能性のある用語に使用します。
-
モデル (オプション): エンド ユーザーの音声の文字起こしに使用するモデルを選択します。
モデル 説明 ユースケース GPT 4.0 文字起こし GPT-4o アーキテクチャ上に構築されています。特にアクセントのある音声、重複する音声、複雑な語彙に対して、Whisper 1よりも低い単語エラー率を実現します。 正確さが優先される場合に、単語エラー率を最も低くするために使用します。たとえば、アクセントのあるスピーチ、技術的な語彙、または低音質を処理する場合などです。 GPT 4.0 ミニ文字起こし GPT 4.0 Transcribe の軽量で高速なバリアント。GPT 4.0 Transcribeよりもレイテンシーが短縮され、コストが低くなります。精度はフルモデルよりも低くなります。 大量導入において、速度とコストの最適なバランスを提供します。ターンあたりの待機時間が会話の質に直接影響する場合に使用します。 手記最高のエクスペリエンスを得るには、GPT 4.0 Mini Transcribe を使用してください。 -
ユーザー言語: 入力オーディオの言語。
すべてのフィールドを設定したら、右上隅にあるチェックマークを選択して入力を検証します。
音声からテキストから音声へ
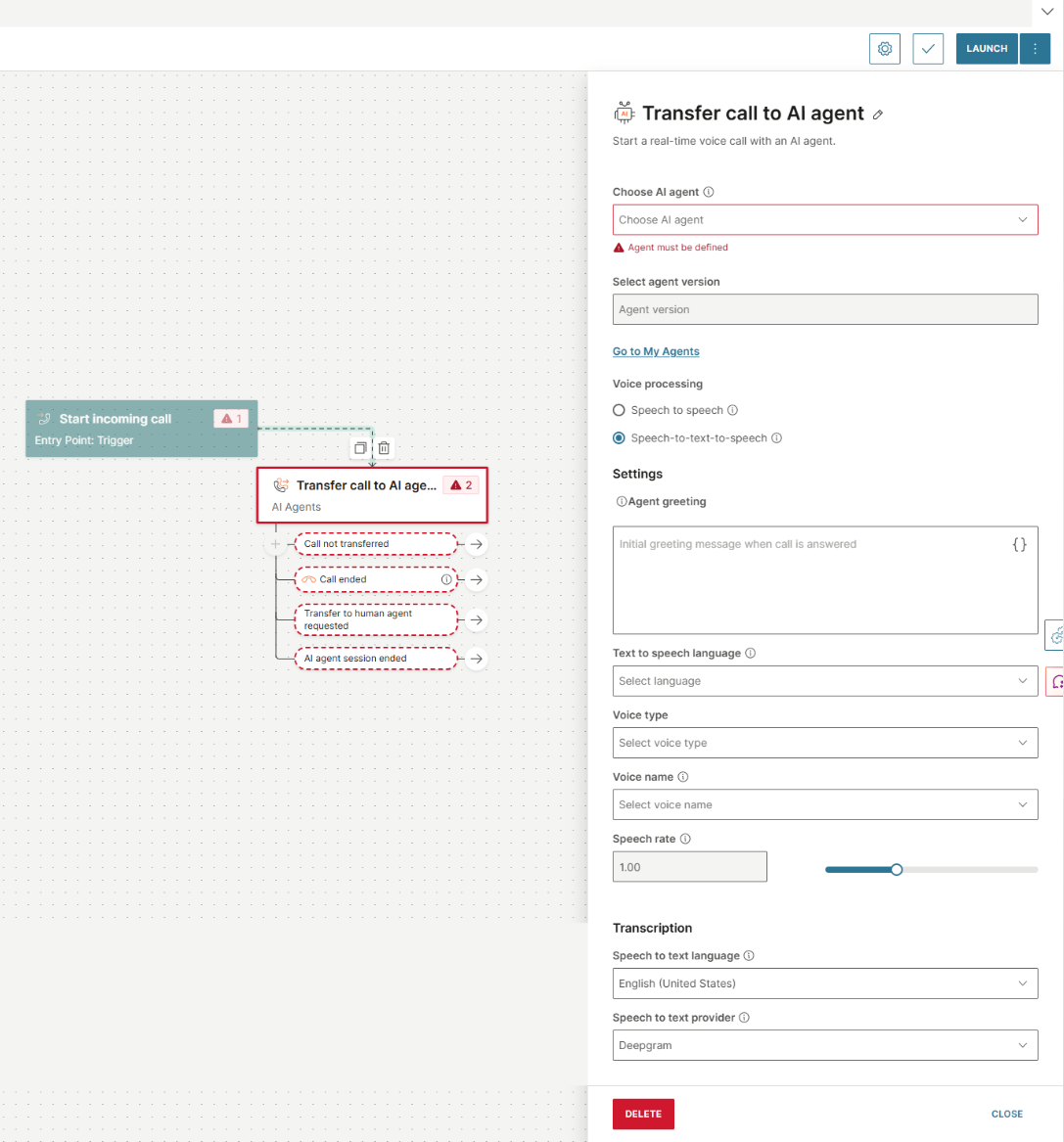
**Speech to text to speechgit ** を選択した場合は、次のフィールドを構成します。
設定
-
エージェントの挨拶: 通話に応答したときにエージェントをトリガーする最初の挨拶メッセージ。
-
テキスト読み上げ言語: これは必須フィールドです。テキストから音声への変換に使用される言語。
-
Voice type: テキストを音声に変換するときに使用される音声。
-
Voice name: 音声名を選択します。
手記ニューラル音声と生成音声には追加料金がかかります。アカウントでニューラル音声と生成音声が利用できない場合は、NTT CPaaS アカウントマネージャーにお問い合わせください。生成音声を使用して、最高のユーザー エクスペリエンスを実現します。 -
発話速度: 発話速度を調整できます。デフォルト値は 1.00 です。
転写
- 音声テキスト言語: これは必須フィールドです。音声認識に使用される言語。
- 音声テキスト変換プロバイダー: 音声認識に使用されるプロバイダー。
すべてのフィールドを設定したら、右上隅にあるチェックマークを選択して入力を検証します。
通話セッションの結果を管理する
AI エージェントへの通話転送 エレメントの次のブランチを使用して、通話セッションの終了後に何が起こるかを管理します。
| 支店 | 通話セッションのステータス |
|---|---|
| 通話が転送されません | フローは IVR (自動音声応答) コールを AI エージェントに転送できませんでした。エンドユーザーと AI エージェントの間で通話セッションが確立されませんでした。IVR (自動音声応答) セッションは、エンド ユーザーとフローの間で続行されます。 たとえば、API 呼び出しが失敗したため、呼び出しは転送されませんでした。 |
| 通話終了 | 通話は、エンドユーザーが電話を切ったか、ネットワークの問題により、転送後に終了しました。この時点からのみ新しい通話を開始できます。 |
| 人間のエージェントへの転送をリクエスト | AIエージェントは、トリガー条件を認識すると、転送要求を実行します。 たとえば、ユーザーが人間のエージェントとの会話を要求した場合、またはAIエージェントがユーザーの要求を解決できないと判断した場合、構成されたツールを呼び出します。エージェントプロンプトでこれらの条件を指定します。ジャーニー自体のさらなるステップを定義します。 |
| AIエージェントセッション終了 | AI エージェントは、通話を個別に終了しません。特定のユーザー入力をセッション終了信号として認識し、通話を終了します。 たとえば、ユーザーは さようなら または これですべてです、ありがとう と言うかもしれません。エージェントはこれらの入力を終了信号として扱い、コールセッションを閉じます。ジャーニー自体のさらなるステップを定義します。 |
音声プロンプトの作成、起動前の検証、およびテストのガイダンスについては、「起動用のVoice AIエージェントの準備](/voice-ai-agents/prepare-voice-ai-agent-for-launch)を参照してください。