AIインサイト
AI分析は、チャットボットとエンドユーザー間の大量の会話を実用的な洞察に圧縮します。これらのインサイトは、高品質のAIチャットボットの構築と強化に役立ちます。
これらの分析情報を使用して、次のことを行います。
- エンドユーザーがチャットボットとどのように対話するかを理解する
- CSATスコアの向上
- ユーザーのコンバージョン率を向上させる
- 会話体験の向上
- エンドユーザーからの実際の要求に基づいた追加のユースケースでチャットボットを強化します
- チャットボットを再トレーニングする
インサイトの種類
次の種類の分析情報を取得できます。
- 〔ダイアログ解析〕(./ai-insights#dialog-analysis)
- トレーニング データの分析情報
- データインサイト
- アクティブラーニング
AI Insights グラフでは、「ラベル」という用語はインテントを指します。
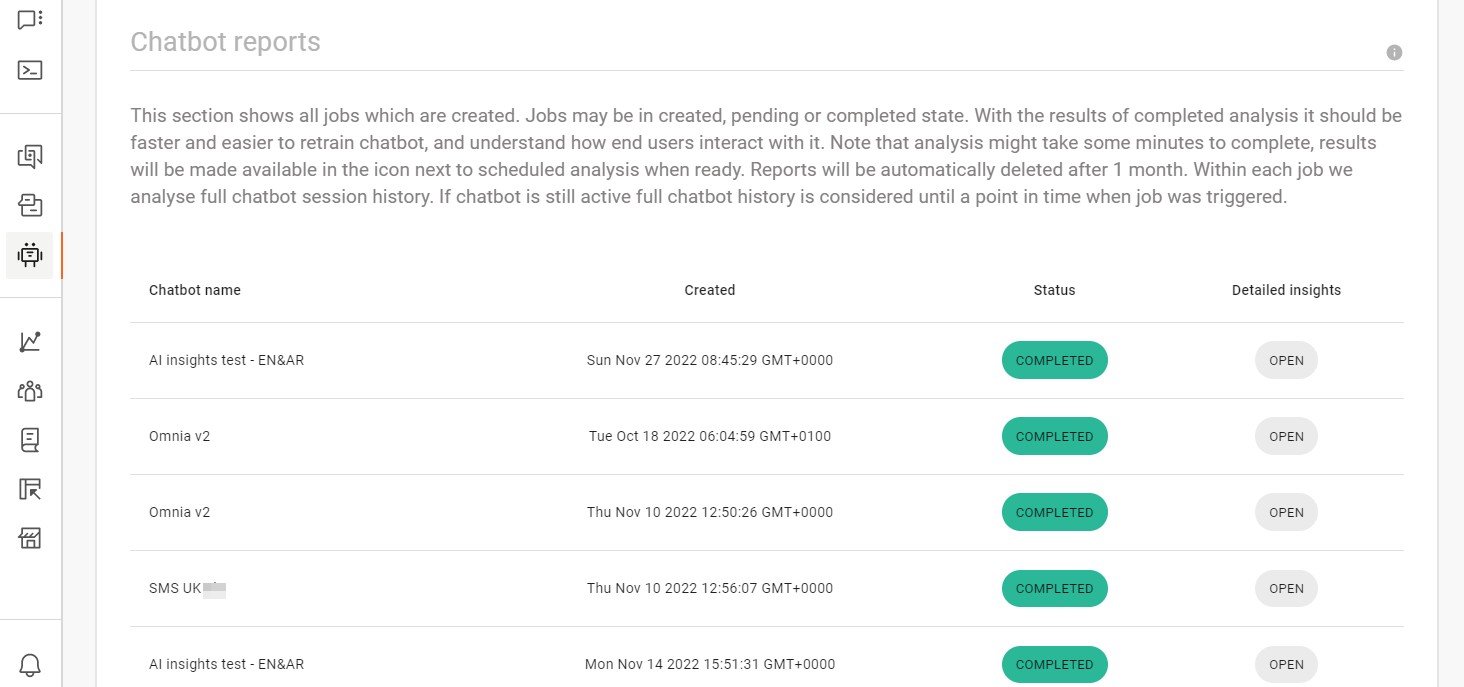
AI Analytics ダッシュボード
これは、AI Insights の既定のビューです。このビューでは、次の操作を実行できます。
- チャットボットの新しい分析ジョブを作成する
- チャットボットの分析ジョブのリストを表示します。各分析ジョブは 1 つのチャットボット用です
- 各分析ジョブについて、次の情報を表示します。
- 名前: チャットボットの名前
- 作成日: ジョブが作成された時刻
- ステータス: 分析ジョブのステータス。ステータスは次のいずれかになります。
- 準備中: この状態は、分析ジョブの Start 分析 をクリックした直後に表示されます。この段階で、分析用のデータが準備されます。
- 作成済み: 分析ジョブは作成されましたが、分析はまだ開始されていません。分析は、リソースが解放されたときに開始されます。
- 保留中: 分析が開始されました。
- 完了。これで解析は完了です。
- エラー: 分析中にエラーが発生しました。そのため、分析は中止されました。
- データなし: チャットボットには、インサイトタイプの分析を開始するためのデータが含まれていません。インサイトタイプのデータが1つでも存在し、そのインサイトタイプのcriteriaが満たされた場合、分析が実行されます。
分析ジョブのステータスが変化すると、テーブルが自動的に更新されます。
- 詳細な分析情報: 完了 分析ジョブの場合は、[開く] をクリックして分析の結果を表示します。
分析ジョブの作成 [#create-an-analysis-job-ai-analytics-dashboard]
チャットボットのすべての インサイトタイプ の結果を取得するには、分析ジョブを 1 つだけ作成する必要があります。
前提 条件 [#prerequisites-ai-analytics-dashboard]
- チャットボットは意図に基づいている必要があります。キーワードチャットボットの場合、ダイアログ分析のみ該当します。
- 分析は、アクティブチャットボットと非アクティブチャットボットの両方に対して実行できます。ただし、チャットボットはしばらくの間アクティブであり、少なくとも 1 つのアクティブなセッションを持っている必要があります。
- トレーニング データ インサイト を除くすべての分析では、チャットボットには少なくとも 1,000 セッションのセッション履歴が必要です。各セッションには、少なくとも 2 つのダイアログが必要です。最良の結果を得るには、チャットボットに 5,000 セッションが必要です。
- トレーニング データ インサイト 分析の場合、チャットボットには少なくとも 2 つの意図が必要です。各意図には、1 語より長いトレーニング フレーズが少なくとも 10 個必要です。
- データインサイト および アクティブラーニング 分析の場合、チャットボットにはエンドユーザーからのメッセージが 1,000 件以上必要です。
- 分析は、セッション履歴全体に対してのみ実行できます。
- チャットボットは、単語がスペースで区切られた言語を使用する必要があります。例:英語。 チャットボットが単語がスペースで区切られていない言語を使用している場合、AIインサイトを取得することはできません。例:中国語、日本語、タイ語、ラオス語。
プロセス [#process-ai-analytics-dashboard]
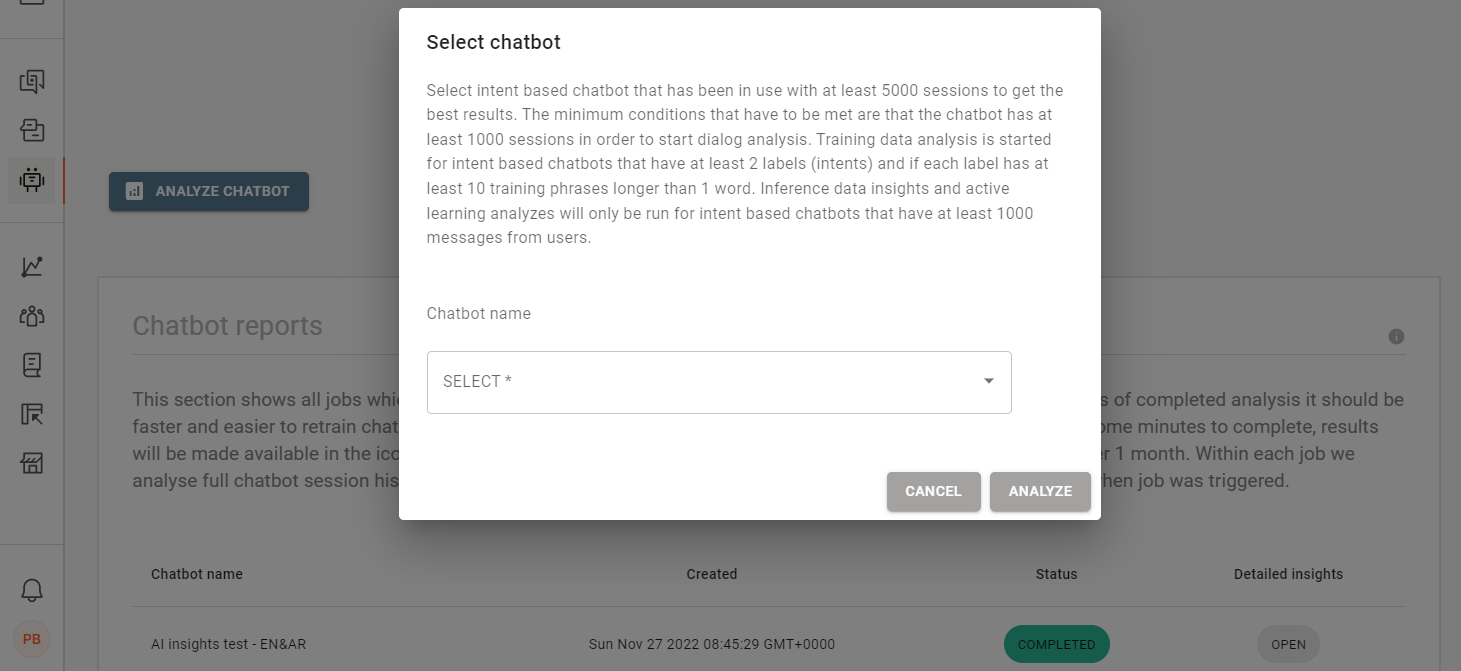
新しい分析ジョブを作成するには、次の手順に従います。
- NTT CPaaS Web インターフェイスで、Answers > AI Insights に移動します。
- [新しい分析の作成] をクリックします。
- 開いたダイアログで、分析するチャットボットを選択します。
- Analyze をクリックして解析を開始します。それ以外の場合は、[キャンセル] をクリックします。
状態が 完了 と表示されたら、分析ジョブに対して [開く] をクリックして結果を表示します。
分析は、チャットボットがアクティブ化された時点から分析が開始された時点までのすべてのデータに対して実行されます。分析開始後の一定期間のデータを分析に含める場合は、新しい分析を実行する必要があります。
分析が完了するまでに数分かかる場合があります。
結果は1か月後に自動的に削除されます。
ダイアログ分析
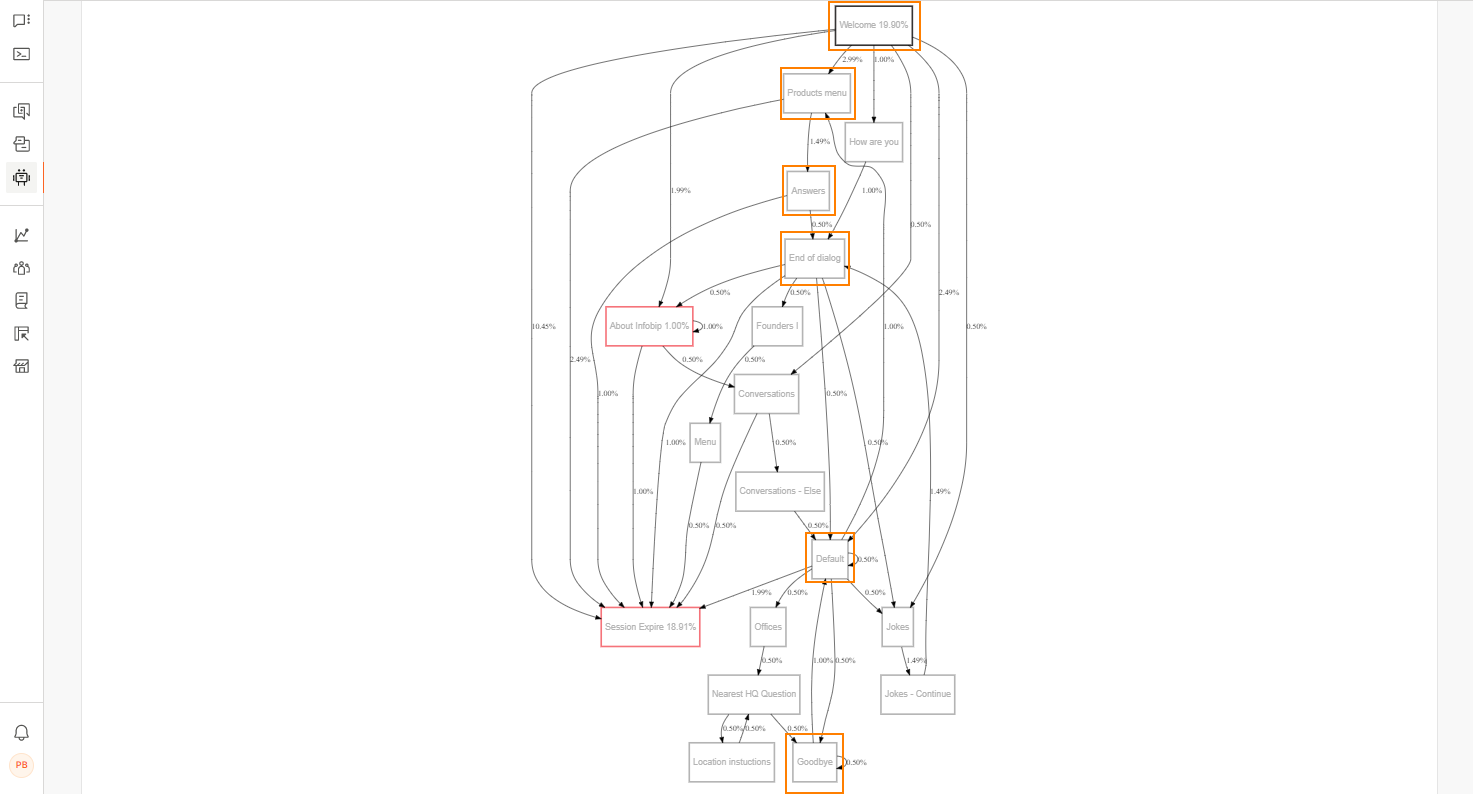
大きなダイアログツリーを持つチャットボットの場合、セッション間で数千のダイアログパスが存在する可能性があります。ダイアログパスは、ユーザーがチャットボットとの対話中にアクセスするダイアログのセットです。ダイアログ パスは、エンド ユーザーがアクセスした最初のダイアログから、セッションを終了するダイアログまで開始します。例: 次の図では、ダイアログ パスの 1 つが ようこそ > 製品メニュー > Answers > ダイアログの終わり > 既定 > さようなら です。
チャットボットのすべてのダイアログパスを視覚化または分析することはできません。ダイアログ分析は、チャットボットのすべてのセッションを評価し、さらに分析するために最もよく使用される20の一意のダイアログパスを特定します。ほとんどの場合、これらの 20 個のダイアログ パスは、すべてのチャットボットのセッションの 50% 以上を表します。
ダイアログ分析は、次のことを理解するのに役立ちます。
- エンドユーザーがチャットボットと対話する方法を理解する
- エンドユーザーがジャーニーをやめる場所を特定する
- コンバージョン率を特定する
ダイアログの詳細 [#dialog-details-dialog-analysis]
このタブでは、次の情報を表示できます。
- 合計セッション数: 分析が実行されたセッションの合計数。これは、チャットボットがアクティブ化されてから分析が開始されるまでのセッションの合計数です
- すべてのセッション内の一意の会話パス: すべてのセッションにわたる一意のダイアログ パスの合計数
- 最も訪問された会話パス: 最も使用されている一意のダイアログパスの数
- 上位パスで表されるセッションの割合: 上位 20 個の一意のダイアログ パスで表されるセッションの割合。
次の例では、2,577 セッションに対して分析が実行されました。これらのセッションには 835 の一意のダイアログ パスがあります。835 個のダイアログ パスのうち、20 個のダイアログ パスが最も頻繁に使用されます。セッションの 53.1% には、これら 20 のダイアログ パスの 1 つ以上が含まれています。

Top 20 Most Visited Paths [#top-20-most-visited-paths-dialog-analysis]
上位 20 のダイアログ パスのそれぞれについて、次の情報を表示できます。
- エンド・ユーザーが開始ダイアログ・パスを入力するセッションの割合
- エンド ユーザーが 1 つのダイアログから次のダイアログに移動するセッションの割合
- ダイアログ中にエンドユーザーがセッションを終了したセッションの割合
すべての割合は、分析に使用されたセッションの合計数に基づいています。
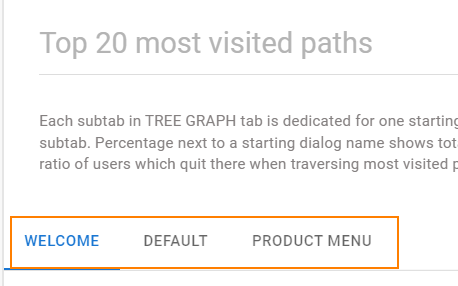
上位 20 個のダイアログ パスは、開始ダイアログごとにグループ化され、これらの各グループは個別のタブに表示されます。 例: 上位 20 個のダイアログ パスのうち、[ようこそ] ダイアログで始まるすべてのダイアログ パスが [ようこそ] タブでグループ化されます。
これらのタブは、頻度の降順で並べ替えられます。次の例では、Welcome は最もよく使用される開始ダイアログであり、Default は 2 番目によく使用される開始ダイアログです。
各タブには、同じ開始ダイアログを持つすべてのダイアログパスを示すグラフが含まれています。
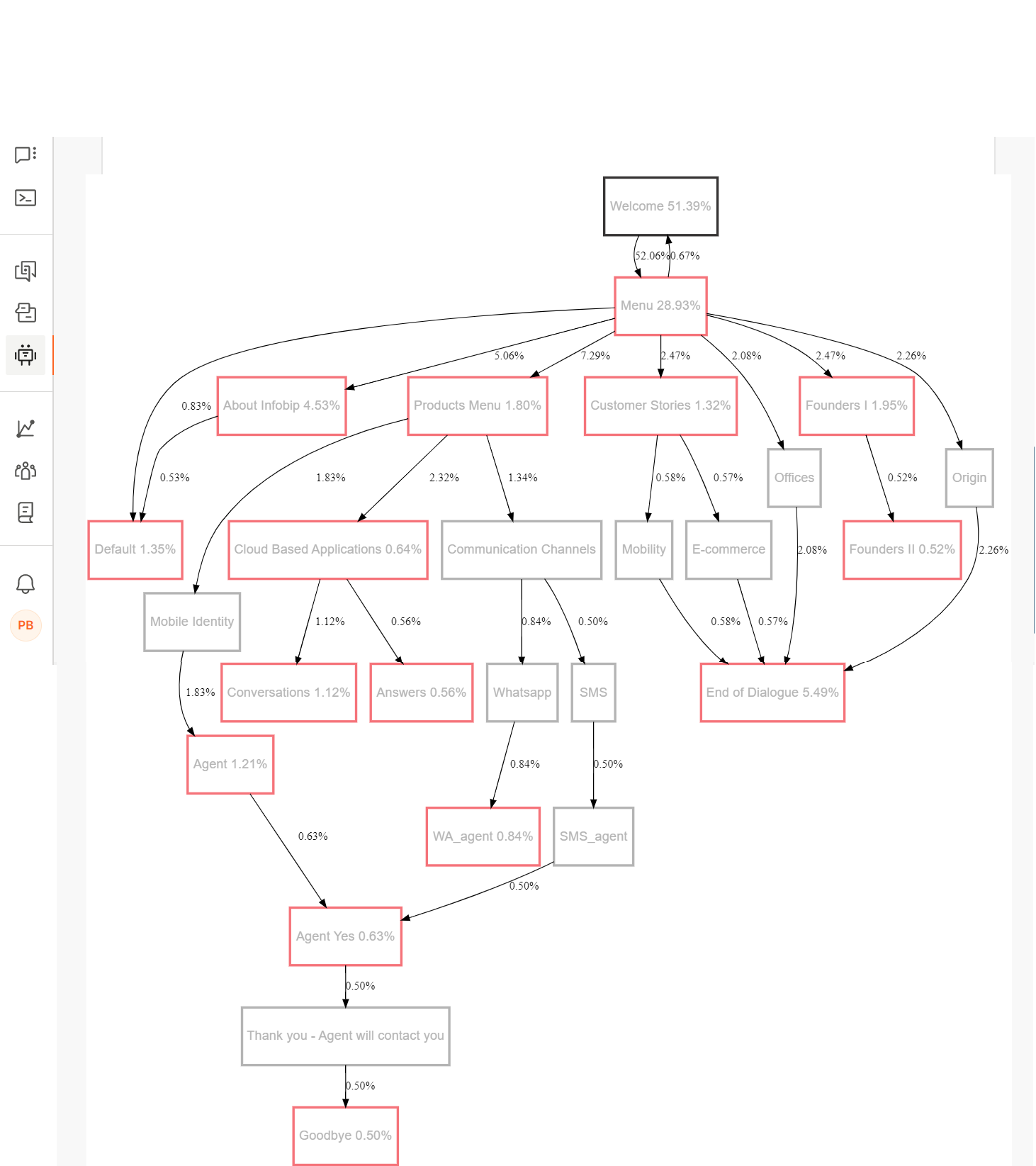
赤い枠線で囲まれたノードはターミナルノードであり、エンドユーザーがセッションを終了したダイアログを示します。例: 次の図では、エンド ユーザーが [メニュー]、[製品メニュー]、および [カスタマー ストーリー] ダイアログでセッションを終了しています。
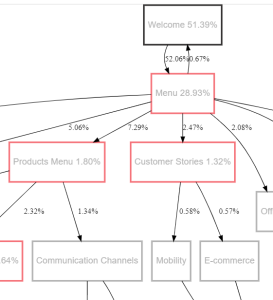
グラフは次のように解釈できます。
- 開始ダイアログの名前の横のパーセンテージは、エンドユーザーが開始ダイアログに入ったセッションの割合を示します。
- ターミナルノードでは、ダイアログ名の横のパーセンテージは、エンドユーザーがそのダイアログでチャットボットセッションを終了したセッションの割合を示します。
- ノードコネクタの横のパーセンテージは、エンドユーザーが1つのダイアログから次のダイアログに移動したセッションの割合を示します。
例: 次の画像では、
- 全セッションの51.39%が「ようこそ」ダイアログで始まりました。
- 全セッションの 52.06% が [ようこそ] ダイアログから [メニュー] ダイアログに移動しました。
- 「メニュー」ダイアログで、次の操作を行います。
- 全セッションの0.67%が「ようこそ」ダイアログに戻りました。
- 全セッションの28.93%がセッションを終了しました。
- 他のセッションは、次のダイアログに移動しました。
- 全セッションの0.83%がデフォルトダイアログに移動しました。
- 全セッションの 5.06% が [NTT CPaaS について] ダイアログに移動しました。
- 全セッションの7.29%が「商品メニュー」ダイアログに移動しました。
- 全セッションの2.47%が「カスタマーストーリー」ダイアログに移動しました。
- 全セッションの2.08%がオフィスダイアログに移動しました。
- 全セッションの2.47%がファウンダーズダイアログに移行しました。
- 全セッションの2.26%がOriginダイアログに移動しました。
ダイアログでセッションを終了するエンド ユーザーの割合が高いが、エンド ユーザーがこのダイアログで終了することを想定していない、または終了したくない場合は、ダイアログの調査が必要になることがあります。考えられる原因は、ダイアログが長すぎるか、混乱しているか、エンドユーザーが必要とする情報がないことです。
トレーニング データ インサイト
AIチャットボットは、トレーニングデータセットを使用して、エンドユーザーとの会話を改善し、エンドユーザーのリクエストを解決します。AIチャットボットのトレーニング・データセットは、インテントとそれに関連するトレーニング・フレーズで構成されます。トレーニング データ インサイトは、これらのトレーニング データセットの品質を評価し、是正措置を特定します。
この分析では、次の処理が行われます。
- インテントのパフォーマンスを示し、パフォーマンスの低いインテントを強調表示します。
- 問題のあるフレーズを特定し、インテントを修正または改善する方法を提案します。
トレーニングデータセットの可視化 [#training-dataset-visualization-training-data-insights]
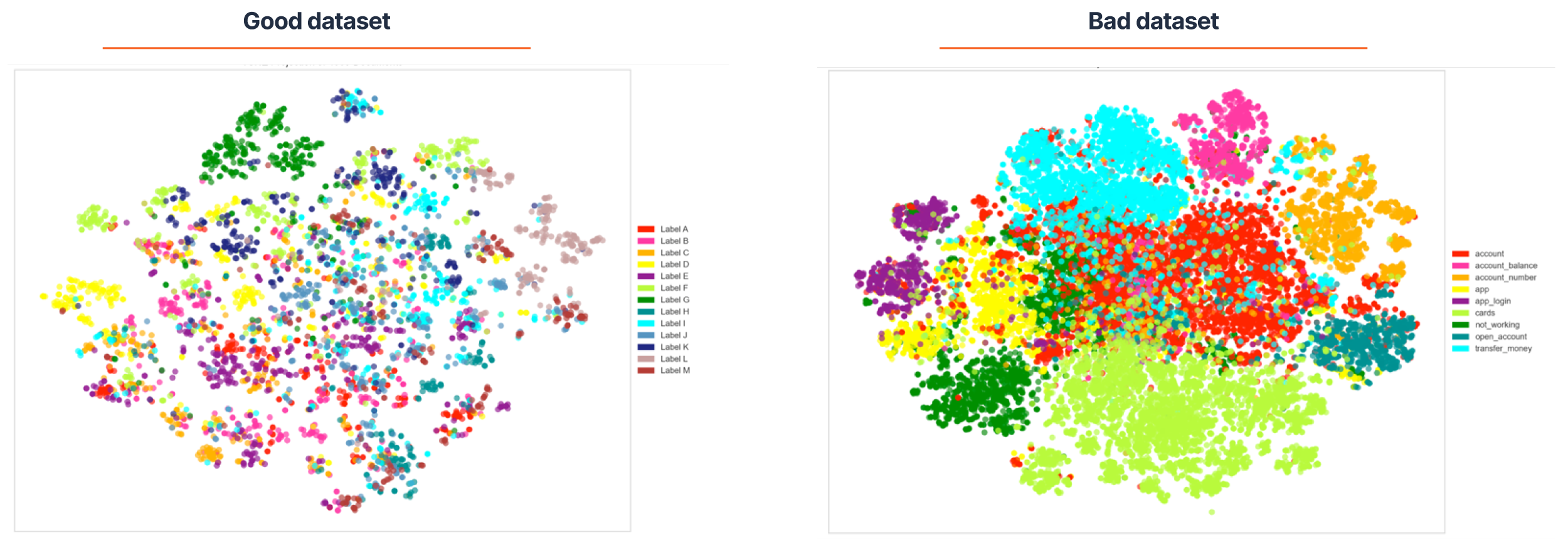
トレーニングデータセットの視覚化は、トレーニングフレーズをクラスターにグループ化します。
グラフでは、各ドットはトレーニングフレーズを表し、各色は意図を表します。トレーニングデータセットが良好な場合、ドット(トレーニングフレーズ)は同じ色のクラスターにグループ化されます。
異なる色のドットが重なっている場合は、これらのトレーニングフレーズのインテントが重なっていることを示します。例: 次の画像では、緑の点の中に赤い点があります。これは、チャットボットでは、トレーニングフレーズが赤の意図に使用されたことを示していますが、分析により、他の同様のトレーニングフレーズが緑の意図に属していることが確認されました。

異なる色のドットが重なり合う数が少ないほど、チャットボットがエンドユーザーのメッセージから意図を認識する可能性が高くなります。
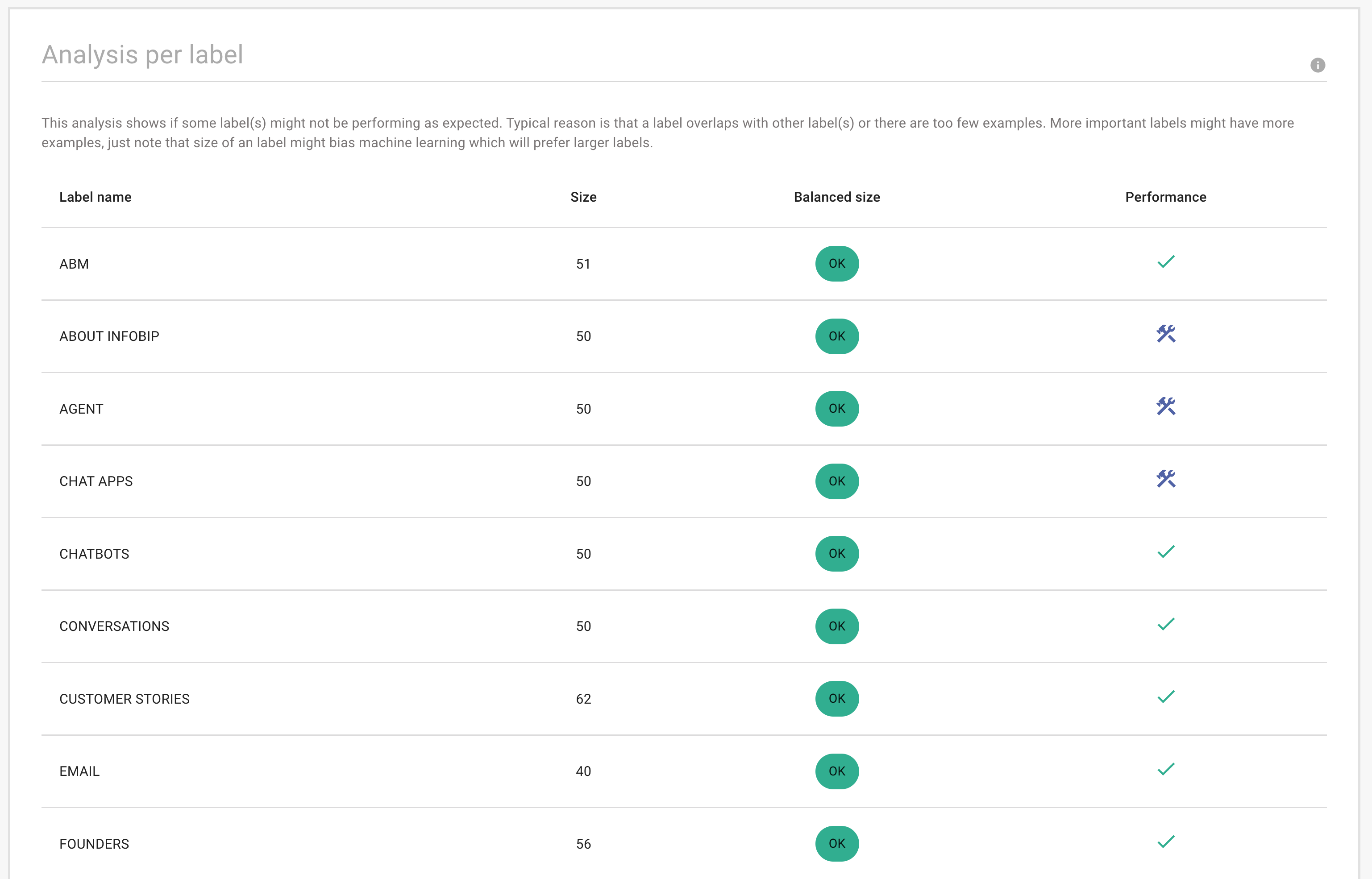
ラベルごとの分析 [#analysis-per-label-training-data-insights]
この分析では、インテントのパフォーマンスがどの程度良好かを示し、パフォーマンスの低いインテントを強調表示して是正措置を講じます。
[ラベルごとの分析] セクションの表には、次の情報が表示されます。
- ラベル名: 意図の名前
- サイズ: 意図のトレーニング フレーズの数
- バランスの取れたサイズ: トレーニング フレーズの数が機械学習に十分かどうかを示します
- パフォーマンス: 意図がうまく機能しているか、改善が必要かを示します。[ツール] アイコンは、意図を改善する必要があることを示します。
インテントのパフォーマンスが低下する原因として考えられるのは、次のとおりです。
- インテントが他のインテントと重複しています。トレーニング・フレーズが一意かどうか、およびこの意図のトレーニング・フレーズが他の意図のトレーニング・フレーズと重複しているかどうかを確認します。
- トレーニングフレーズが不十分です。重要なインテントにトレーニング・フレーズを追加する必要がある場合があります。インテントに多数のトレーニングフレーズが含まれていると、チャットボットのトレーニングが容易になります。
データインサイト
データインサイトは、チャットボットのパフォーマンスとエンドユーザーの会話エクスペリエンスを向上させるのに役立ちます。分析では、チャットボットの再トレーニングに最適な実際のエンドユーザーデータが使用されます。
この分析では、次の情報が得られます。
- 言語分布すべてのメッセージ - チャットボットに設定された言語以外に、エンドユーザーが最もよく使用する言語はどれですか?
- インテントの配布 - エンド ユーザーから最も頻繁に寄せられるクエリは何ですか?めったに使用されないインテントをチャットボットから削除できますか?
- 少なくとも 1 つの [不明な単語]を含むメッセージの比率 (./ai-insights#unknown-words-data-insights)- チャットボットは適切にトレーニングされていますか?
- 意図間のエンティティ分布- チャットボットはNER属性を最大限に活用していますか、それともエンドユーザーは何度も繰り返す必要がありますか?チャットボットにはどのエンティティが必要ですか?
- 長いメッセージ- 主にチャットボットで処理するように設計されておらず、個別に調査する必要があるメッセージはありますか?
すべてのグラフはインタラクティブです。
- グラフのセクションにカーソルを合わせると、詳細が表示されます。
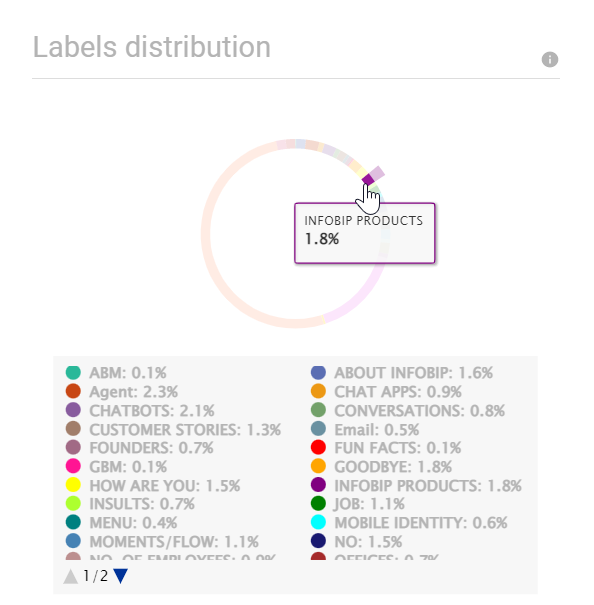
- グラフのセクションをクリックすると、そのセクションを強調表示できます。
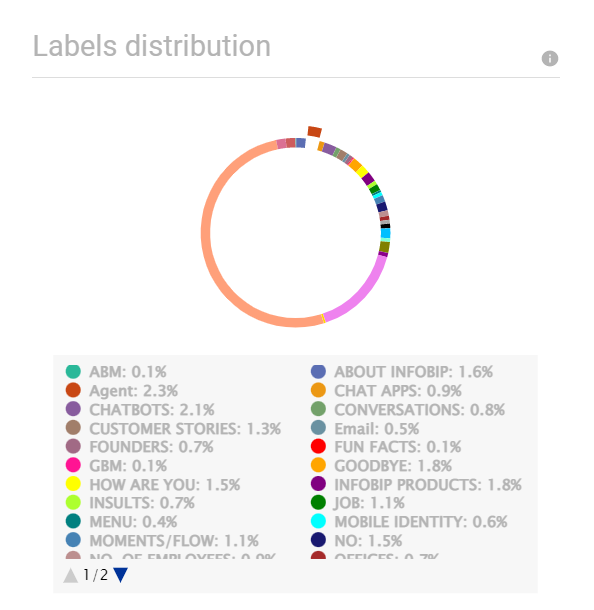
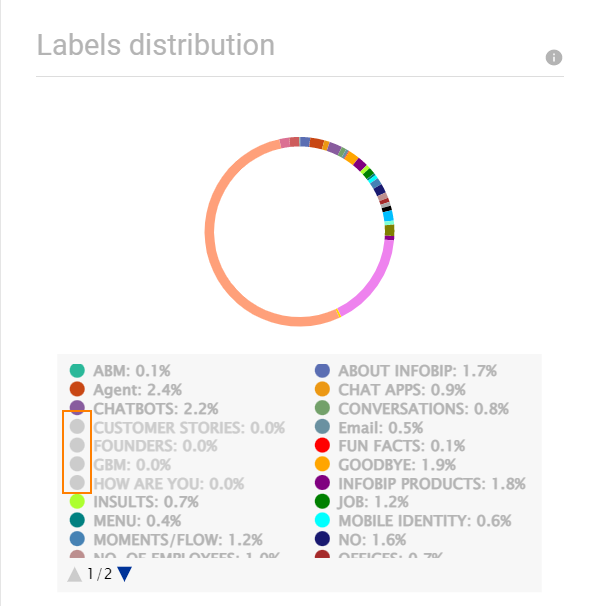
- グラフの下の凡例で、ドットをクリックしてグラフに項目を追加または削除できます。例: 次の図では、輪郭が描かれているラベルがグラフから除外されています。
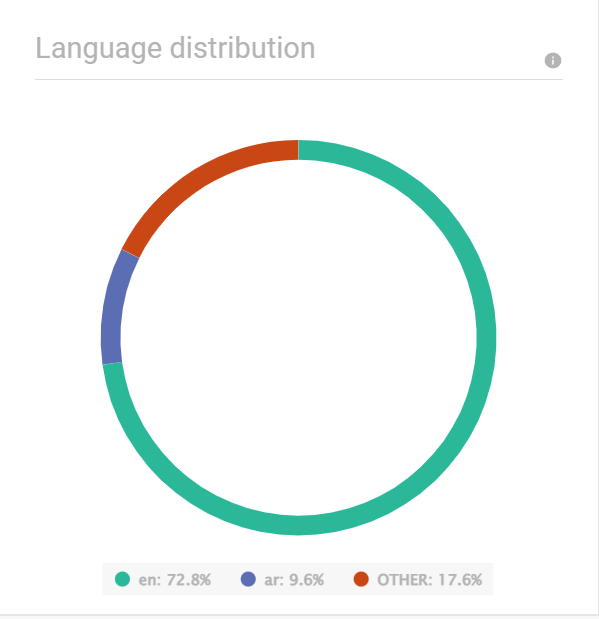
言語の分布 [#language-distribution-data-insights]
言語分布グラフは、エンド ユーザーが送信したメッセージ全体の言語の分布を示します。分析では、次の言語が認識されます。
af、als、am、an、ar、arz、as、ast、av、az、azb、ba、bar、bcl、be、bg、bh、bn、bo、bpy、br、bs、bxr、ca、cbk、ce、ceb、ckb、co、cs、cv、cy、da、de、diq、dsb、dty、dv、el、eml、en、eo、es、et、eu、fa、fi、fr、frr、fy、ga、gd、gl、gn、gom、gu、 GV、彼、こんにちは、hif、hr、hsb、ht、hu、hy、ia、id、ie、ilo、io、is、it、ja、jbo、JV、KA、kk、km、kn、ko、krc、ku、kv、kw、ky、ky、la、lb、lez、li、lmo、lo、lrc、lt、lv、mai、mg、mhr、min、mk、ml、mn、mr、mrj、ms、mt、mwl、my、myv、mzn、いいえ、nap、nds、 ne、新しい、nl、nn、no、oc、または、os、pa、pam、pfl、pl、pms、pnb、ps、pt、qu、rm、ro、ru、rue、sa、sah、sc、scn、sco、sd、sh、si、sk、sl、so、sq、sr、su、sv、sw、ta、te、tg、th、tk、tl、tr、tt、tyv、ug、uk、ur、uz、vec、vep、vi、vls、vo、wa、 戦争、wuu、xal、xmf、李、陽、越、zh
チャットボットの言語が最も代表的な言語と異なる場合は、チャットボットを変更してパフォーマンスを向上させることができます。
グラフでは、メッセージ数が 5% 以下のすべての言語が [その他] としてグループ化されます。
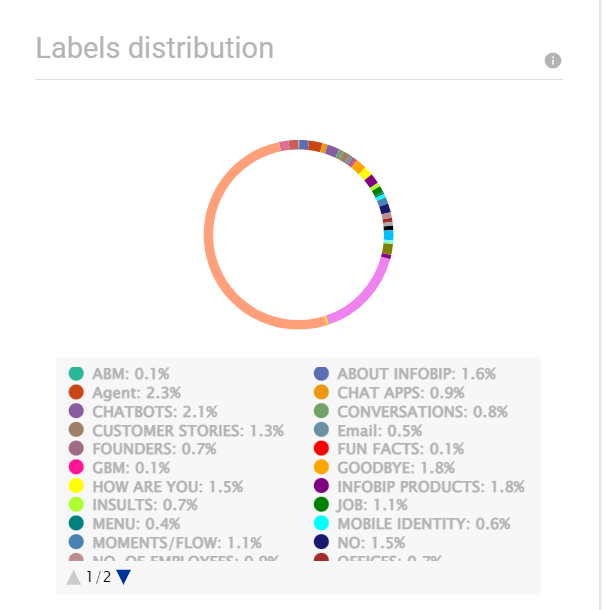
ラベルの配布 [#labels-distribution-data-insights]
ラベルの分布グラフには、エンドユーザーが送信したメッセージ全体のインテントの分布が表示されます。例: 次のグラフでは、エンド ユーザーからのメッセージの 0.2% が ABM の意図に対するものです。
「不明」ラベルは、意図を特定できなかったメッセージを示します。
ラベル分布分析は、適切に設計された大規模なチャットボットにのみ役立ちます。この分析は、小型のチャットボットや設計が不十分なチャットボットには役に立ちません。
未知の単語 [#unknown-words-data-insights]
不明な単語のグラフを使用して、トレーニングデータセットがエンドユーザーのメッセージにどの程度関連しているかを特定します。
エンドユーザーがダイアログに入ると、チャットボットはエンドユーザーのメッセージの意図を特定しようとします。不明な単語の分析では、エンド ユーザーのメッセージ内の単語をこの意図のトレーニング データセットと比較し、トレーニング データセットの一部ではない単語を特定します。このような場合は、アクティブ ラーニング セクションで、より実用的な分析情報を確認してください。例: Concepts セクションには、新しい概念、インテント、トピック、またはトレーニング フレーズが含まれる場合があります。または、Unknown Labelsセクションを確認してください。
グラフは、不明な単語を少なくとも 1 つ含むメッセージの割合を示します。理想的には、この割合は 20% 未満である必要があります。未知の単語を使用してチャットボットを再トレーニングすると、この割合は減少します。
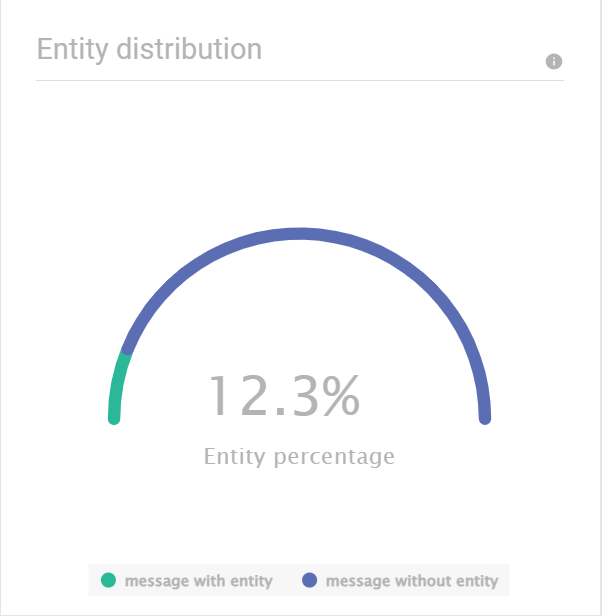
エンティティの分布 [#entity-distribution-data-insights]
[エンティティ分布] グラフには、エンティティを含むエンド ユーザー メッセージの割合が表示されます。例: 次のグラフでは、エンド ユーザー メッセージの 17.5% にエンティティが含まれています。
多くのエンド ユーザー メッセージにエンティティが含まれているが、エンティティ機能を有効にしていない場合は、この機能を有効にしてエンド ユーザー エクスペリエンスを向上させることを検討してください。
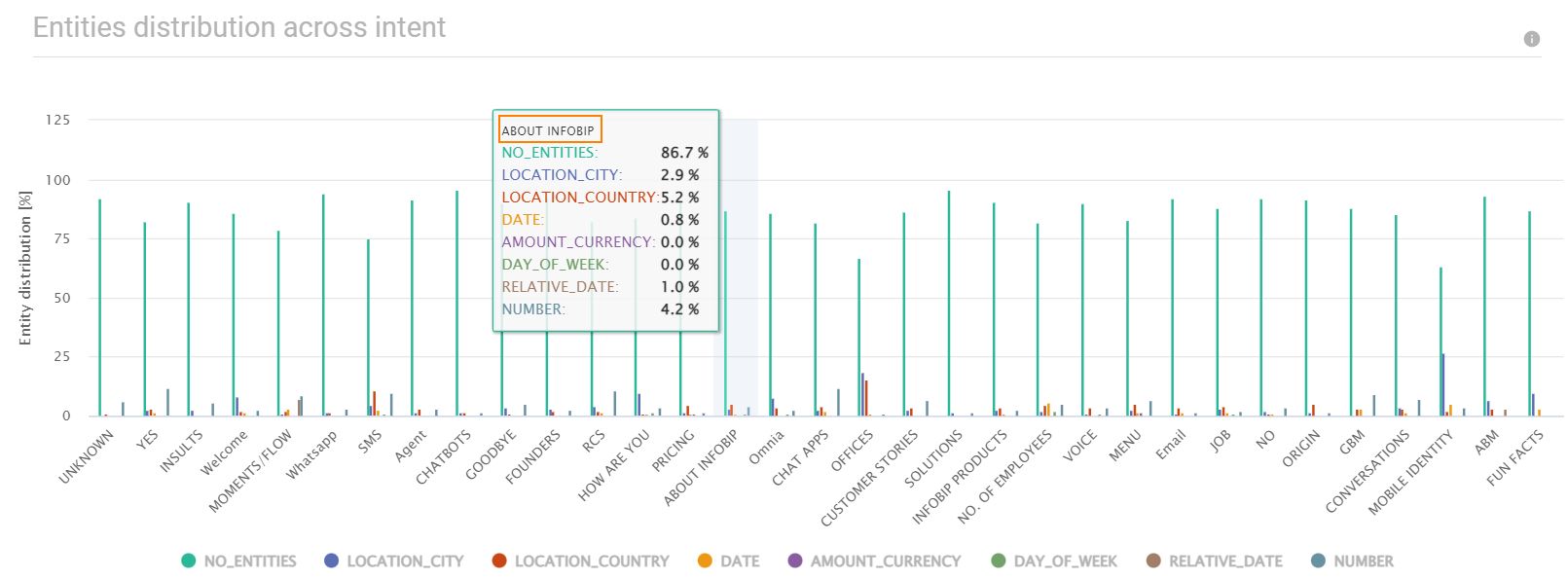
インテント間でのエンティティの分布 [#entity-distribution-across-intent-data-insights]
このグラフは、意図間のエンティティの分布を示しています。
分析には、標準エンティティのみが含まれます。ユーザー定義エンティティは含まれません。
このグラフを使用して、エンド ユーザー メッセージ内のエンティティの出現を識別します。例:次の図では、About_Infobip意図のエンドユーザーメッセージの5.2%にLocation_Countryエンティティが含まれています。これは、これらのメッセージでエンドユーザーが国について言及していることを示しています。同様に、Location_Countryエンティティは、他のインテントのメッセージに存在します。このエンティティをチャットボットに追加すると、チャットボットはエンドユーザーのメッセージから国を抽出でき、エンドユーザーに国を尋ねる必要はありません。
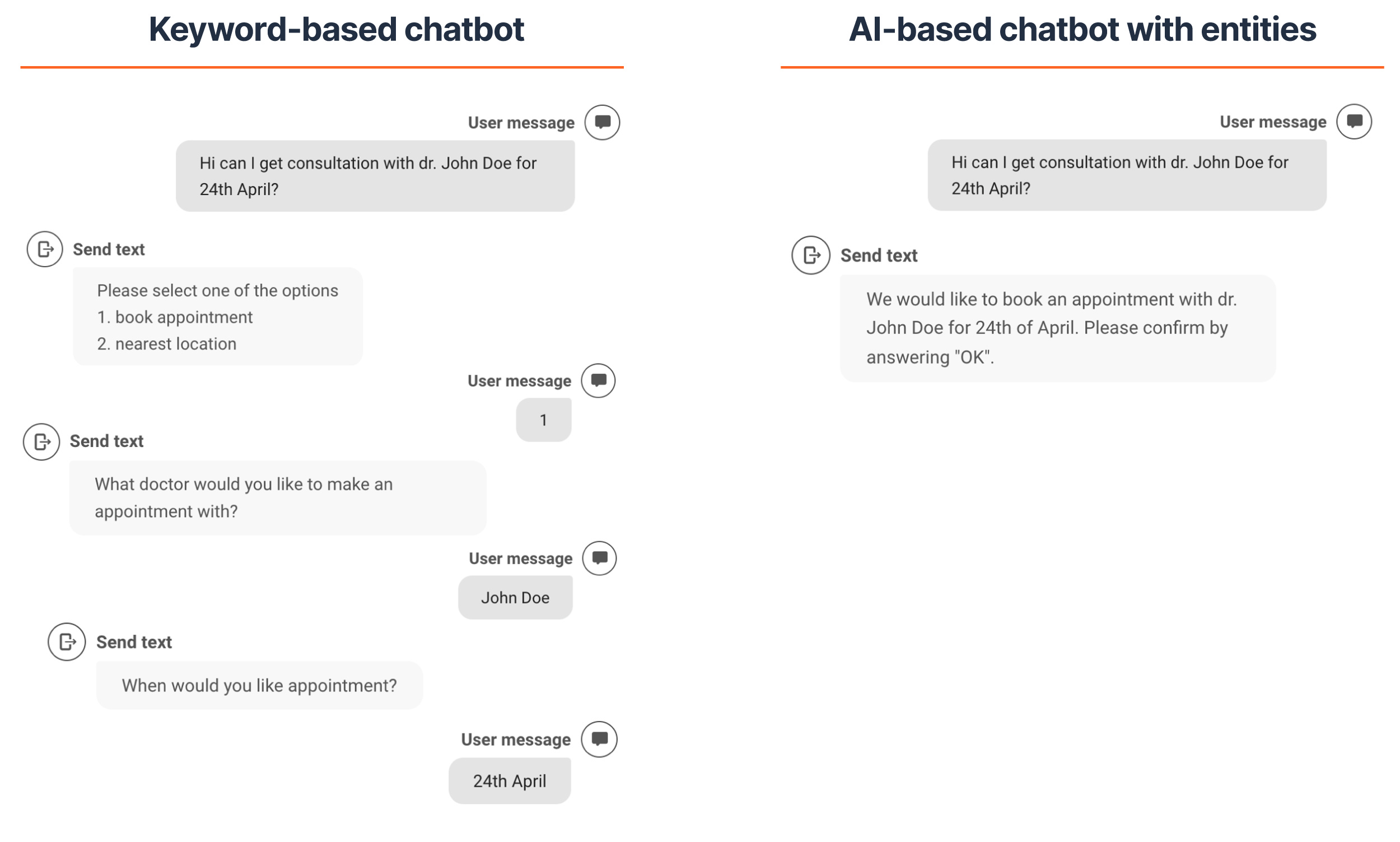
次の図は、チャットボットと、予定を予約するエンド ユーザーとの間の会話を示しています。この画像は、キーワードベースのチャットボットと、エンティティが有効になっている AI ベースのチャットボット用です。
キーワードチャットボットは、割り当てられたキーワードに基づいて機能します。チャットボットがエンドユーザーのメッセージでこれらのキーワードを見つけられない場合、チャットボットはデフォルトのフローを使用します。これは、繰り返しとユーザーエクスペリエンスの低下につながります。この例では、エンド ユーザーは予定を予約するために必要な情報を提供しています。ただし、メッセージには設定されたキーワードが含まれていないため、チャットボットはエンドユーザーに情報を要求します。
AI チャットボットは、エンド ユーザーのメッセージ内の次のエンティティを認識します。
- 人物:ジョン・ドウ博士
- 開催日:4月24日(土)
そのため、AIチャットボットはエンドユーザーに情報を尋ねる必要はありません。エンド ユーザーは、より高速な応答を得ることができ、より優れたユーザー エクスペリエンスを得ることができます。
長いメッセージ [#long-messages-data-insights]
長いメッセージ分析は、チャットボットとエンドユーザーの間の会話からすべての長い文を抽出します。これらのメッセージは、チャットボットが処理するように設計されていないマーケティングキャンペーンやその他のリクエストである可能性があります。ビジネス・ユーザーは、これらのメッセージを評価し、関連するアクションを実行できます。この分析はチャットボットデザイナーを対象としたものではありませんが、ビジネスユーザーが顧客満足度を向上させるためのオプションを提供します。

Answers Web インターフェイスで長いメッセージを表示するか、[ダウンロード] をクリックしてファイルを.csv形式でダウンロードできます。
アクティブラーニング
アクティブラーニングを使用して、チャットボットの精度を高めるデータポイントを特定します。分析では、チャットボットの再トレーニングに最適な実際のエンドユーザーデータが使用されます。
この分析では、次の情報が得られます。
- エンド ユーザー メッセージから会話トピックを特定する
- インテントで処理されないトピックの検出
- チャットボットの再トレーニングに使用できる有用なメッセージを抽出する
アクティブラーニング分析は言語によって行われます。分析は、エンド ユーザー メッセージの 30% 以上で使用されている言語ごとに実行されます。各言語の結果は、個別のタブに表示されます。
言語はページの上部に表示されます。言語分布の詳細は、[Data Insights] タブで確認できます。

アクティブラーニングは次のように分類されます。
- 概念: エンド ユーザー メッセージから潜在的なトピックを検出します。これらの概念を新しいインテントとして追加したり、概念をトレーニングフレーズとして使用したりして、チャットボットの精度を向上させることができます。
- 不明なラベル: トレーニング データに表示されない単語の大部分で構成されるメッセージ。これらの単語を確認し、既存のインテントに新しいトレーニング・フレーズとして追加するかどうかを決定できます。
- 不確かな決定: チャットボットがメッセージの意図を判断できない場合。パフォーマンスを向上させるには、トレーニング データセットに関連するメッセージを追加します。
コンセプト [#concepts-active-learning]
この分析では、エンド ユーザー メッセージ内のトピック (概念) を表す単語のペアを検出します。概念に関連するすべてのメッセージを評価し、チャットボットに関連するメッセージを特定します。概念が既存の意図に適用可能な場合は、関連するメッセージを意図のトレーニングデータセットに追加します。コンセプトが一意な場合は、新しい意図を作成し、関連するメッセージをトレーニングフレーズとして新しい意図に追加し、意図をチャットボットに組み込みます。
次の例は、分析によって、トレーニング データセットにはなかった新しい概念 PCR ↔ TEST が特定されたことを示しています。
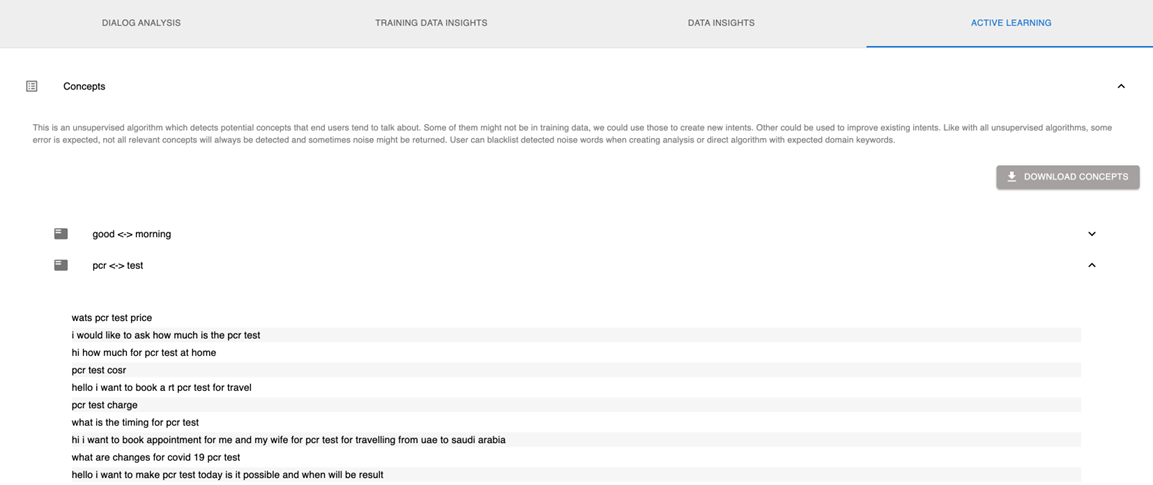
この分析は教師なしアルゴリズムを使用しているため、結果が正確でない可能性があります。分析では、関連するすべての概念が検出されるわけではなく、無関係な概念も検出される場合があります。
解析結果を.csv形式でダウンロードします。[コンセプトのダウンロード] をクリックします。
不明なラベル [#unknown-labels-active-learning]
この分析では、これらのメッセージ内のほとんどの単語が意図のトレーニングデータセットに存在しないために、意図を特定できなかったエンドユーザーメッセージを特定します。これらのメッセージを確認し、チャットボットに関連するメッセージを特定します。メッセージが既存の意図に適用可能な場合は、これらのメッセージを意図のトレーニングデータセットに追加します。それ以外の場合は、新しい意図を作成し、関連するメッセージをトレーニングフレーズとして新しい意図に追加し、意図をチャットボットに組み込みます。
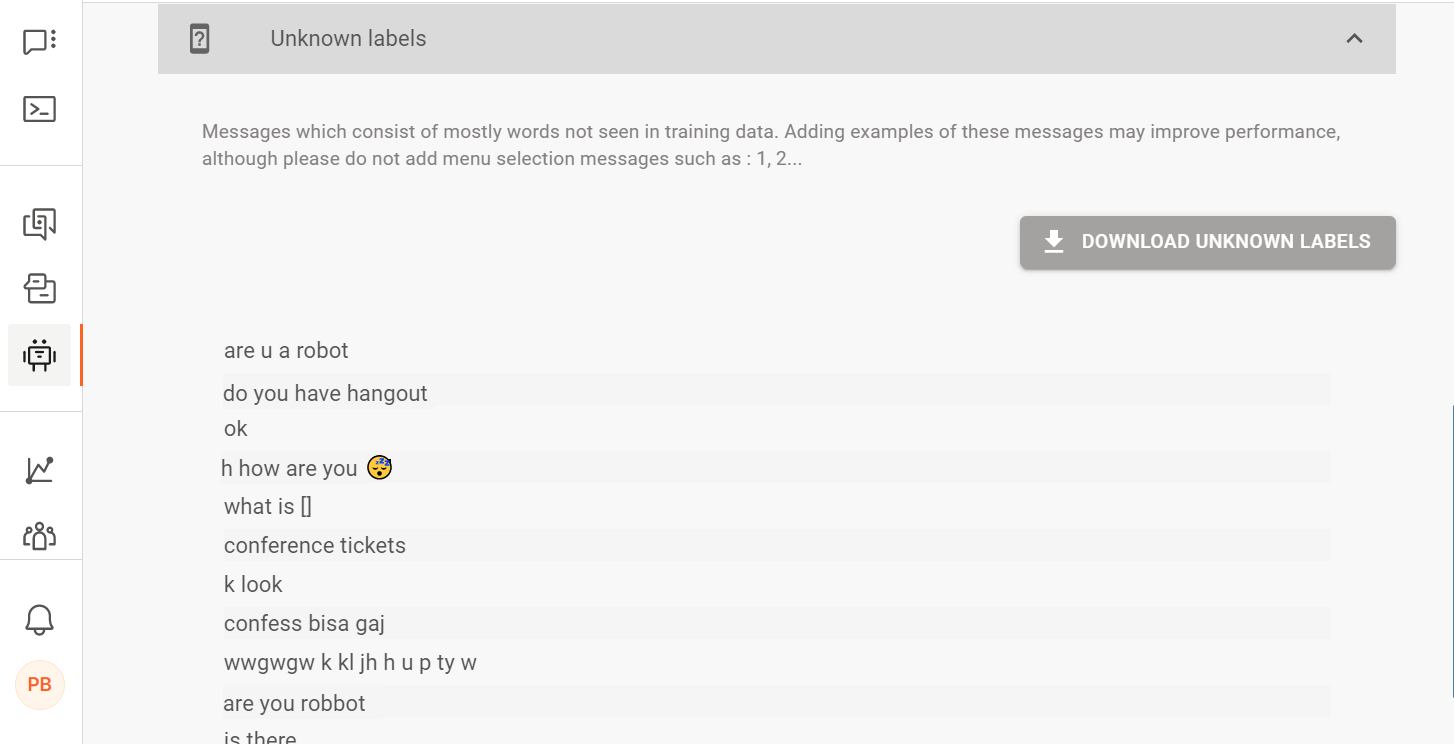
結果を.csv形式でダウンロードします。Download unknown labels をクリックします。
不確実な決定 [#uncertain-decision-active-learning]
この分析では、意図を特定できなかったエンド ユーザー メッセージを特定します。原因のいくつかは次のとおりです。
- この分析では、複数の機械学習モデルを使用して、これらのモデルが同じ意図で結論付けることができなかったメッセージを特定します。考えられる原因は、トレーニング・データセットの品質が低いか、トレーニング・フレーズが重複しているインテントである可能性があります。これらのメッセージをトレーニング フレーズとして関連する意図に追加します。
- 自動修正後にメッセージに対して認識された意図は、自動修正前に認識された意図とは異なります。これらのメッセージを評価し、正しい意図にトレーニング フレーズとして追加します。

結果を.csv形式でダウンロードします。Download uncertain decision をクリックします。
ベストプラクティス
チャットボットのパフォーマンスは、トレーニングデータセットの質と量によって異なります。チャットボットがエンドユーザーのメッセージの意図を正しく識別し、それに応じて応答できるように、適切なトレーニングデータセットを用意することが重要です。
このセクションでは、インテントに適したトレーニングデータセットを作成する方法について説明します。
適切なデータセットを作成する [#create-a-good-dataset-best-practices]
適切なデータセットは、次の方法で作成できます。
- エンドユーザーからチャットボットに送信されたメッセージを使用します。
- AIチャットボットのデータセット作成を専門とするパートナーからデータセットを購入します。詳細については、NTT CPaaS アカウント マネージャーにお問い合わせください。
- Answersのアクティブラーニング機能を使用して、新しい関連データを収集します。
類似インテントの回避 [#avoid-similar-intents-best-practices]
同じ目的を持つ複数のインテントがないことを確認してください。
例: CarA、Car B、Car C など、10 台の車種があります。各モデルの意図は次のとおりです。
意 | トレーニングフレーズ | エンティティ |
|---|---|---|
| Buy_CarA | どのCarAモデルの在庫がありますか? CarAのリースオプションはありますか? | カーラ |
| Buy_CarB | どのCarBモデルの在庫がありますか? CarBのリースオプションはありますか? | 炭水化物 |
| Buy_CarC | どのCarCモデルの在庫がありますか? CarCのリースオプションはありますか? | CarC(カーシー) |
| ... |
この例では、すべてのインテントの目的は同じで、特定のモデルの車を購入することです。
これらのインテントのトレーニング・フレーズも同じです。インテントのすべてのトレーニングフレーズでこのような重複や類似性が発生した場合、チャットボットは状況を正しく管理できない可能性があります。例: 終了ユーザーメッセージに車種が含まれていない場合、チャットボットはインテント(Buy_CarA、Buy_CarBなど)をランダムに認識します。
この問題を回避するには、次の操作を行います。
- インテントをマージして 1 つの意図を作成します。例: Buy_Car.
- エンティティのカスタム データ型を作成し、値を追加します。例: model{CarA, CarB, CarC, ...} です。
- NER属性を作成します。例: model 型の car 属性。
- 意図に NER 属性を割り当てます。例: 車をBuy_Carに割り当てます。
- 取得したエンティティ値に基づいてチャットボットを分岐します。例: CarA
個別インテントでの類似または同一のトレーニング・フレーズの回避 [#avoid-similar-or-identical-training-phrases-in-discrete-intents-best-practices]
インテントの目的が異なる場合は、これらのインテントに類似または同一のトレーニング・フレーズがないことを確認してください。
次の例では、Model と Product の 2 つの意図に異なる目的があります。しかし、トレーニングフレーズは似ています。そのため、チャットボットはエンドユーザーのメッセージの正しい意図を識別できない場合があります。
意 | トレーニングフレーズ |
|---|---|
| モデル | 車はどのモデルですか? |
| 積 | 車のモデルは何ですか? |
トレーニングフレーズでのバリエーションの使用 [#use-variations-in-training-phrases-best-practices]
意図として、トレーニングフレーズにバリエーションがあることを確認します。
例: Exchange_Currency 意図の場合、トレーニング フレーズは次のとおりです。
- EURからUSDに変更したいのですが。
- EURからGBPに変更したいのですが。
- USDからEURに変更したいのですが。
- USDからGBPに変更したいのですが。
- GBPからEURに変更したいのですが。
- GBPからUSDに変更したいのですが。
エンド ユーザーがメッセージの異なるバリエーションを送信すると、チャットボットが意図を識別できない場合があります。
例:エンドユーザーのメッセージは「米ドルを英国ポンドに変換したい」です。
このメッセージは、「I would like to change from USD to GBP」というトレーニング フレーズのバリエーションです。チャットボットは「I」や「to」などの単語を無視するため、エンドユーザーのメッセージとトレーニングデータセットの間に重複する単語はありません。そのため、チャットボットはメッセージに Exchange_Currency 意図を割り当てることができません。
十分な数のトレーニングフレーズを使用する [#use-sufficient-number-of-training-phrases-best-practices]
意図にトレーニングフレーズがほとんどない場合、チャットボットには意図を正しく識別する方法を学習するのに十分なデータがありません。意図のトレーニングフレーズの数が多いほど、エンドユーザーが関連するメッセージを送信したときに、チャットボットがこの意図をより適切に識別できます。
検証を完了するには、意図に少なくとも 10 個のトレーニング フレーズを追加する必要があります。この数には、トレーニング フレーズのみが含まれ、キーワードは含まれません。NTT CPaaS では、少なくとも 100 個のトレーニング フレーズを追加することをお勧めします。最高のパフォーマンスを得るには、少なくとも 400 個のトレーニング フレーズを追加します。
頻繁に出現する単語のトレーニングフレーズをさらに作成する [#create-more-training-phrases-for-frequently-occurring-words-best-practices]
単語のトレーニングフレーズの数は、その出現頻度に基づいている必要があります。エンド ユーザー メッセージで単語が頻繁に使用される場合は、この単語を含むトレーニング フレーズをさらに追加します。例: エンド ユーザー メッセージの 70% で「money」という単語が使用され、「current」という単語がメッセージの 2% でしか使用されていない場合は、「money」という単語を含むトレーニング フレーズをさらに作成します。
- 私の口座にはどのくらいのお金がありますか?
- お金を見せて
- 私はどのくらいのお金を持っていますか?
トレーニングデータセットのサイズのバランスを取る [#balance-the-training-dataset-size-best-practices]
すべてのインテントのサイズが類似している場合、チャットボットは各意図に同じ優先度を割り当てます。重要度の低い意図がエンド ユーザーのメッセージに割り当てられる場合があります。この問題を回避するには、重要なインテントのトレーニング・データセットが、重要度の低いインテントのトレーニング・データセットよりも大きいことを確認します。例: 銀行の場合、住宅ローンの意図は、ウェルカムとさようならの意図よりも重要です。
複数のインテントを使用する代わりにエンティティタイプに基づいて分岐する [#branch-based-on-entity-types-instead-of-using-multiple-intents-best-practices]
場合によっては、複数の意図を作成する代わりに、エンティティの種類に基づいて分岐できます。
例: 次のインテントの場合、エンドユーザーのメッセージは類似している可能性がありますが、唯一の違いはアクション(予約、キャンセル、または再スケジュール)です。
意 | トレーニングフレーズ | アクション |
|---|---|---|
| Book_Appointment | 予約をしたいです。 ご予約をお願いいたします。 | 本 |
| Cancel_Appointment | 予約をキャンセルしたいです。 予約をキャンセルしてください。 | キャンセル |
| Reschedule_Appointment | 予約を変更したいです。 予約を延期する必要があります。 予約を移動したいです。 | 変更する |
アクションごとに個別のインテントを使用する代わりに、次の操作を実行できます。
- インテントをマージして 1 つの意図を作成します。例: 予定。
- 各アクションのカスタムデータ型を作成し、値を追加します。例:
- エンティティ ブック = {ブック, 予約}
- エンティティ_キャンセル = {キャンセル, キャンセル}
- エンティティ再スケジュール = {移動、再スケジュール、延期、前払い}
- 名前付きエンティティ認識 (NER) を使用し、これらのエンティティの種類を意図に追加します。
- 取得したエンティティの種類に基づいてチャットボットを分岐します。例: エンティティ ブック。
競合するインテントの検出 [#detect-conflicting-intents-best-practices]
Training Data Insights を使用して、競合するインテントを特定します。
その後、次のオプションを試して問題を解決できます。
- インテントをマージします。
- エンティティに基づいて分岐します。エンティティタイプに基づくブランチおよび類似インテントの回避セクションの例を参照してください。